
Evolutionary Reinforcement Learning
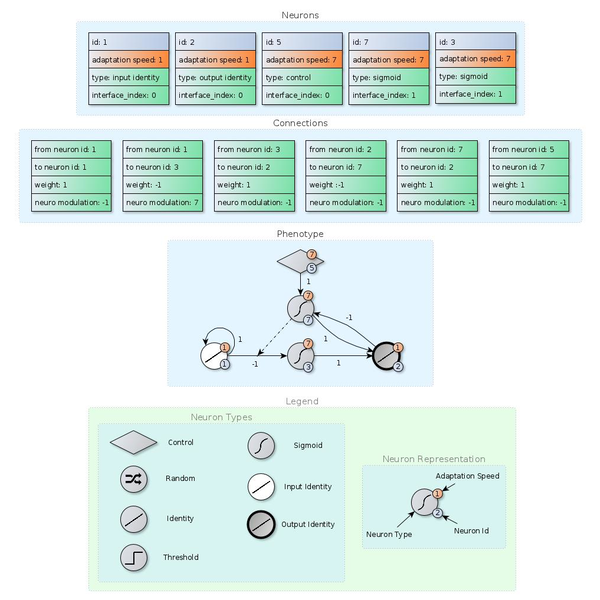
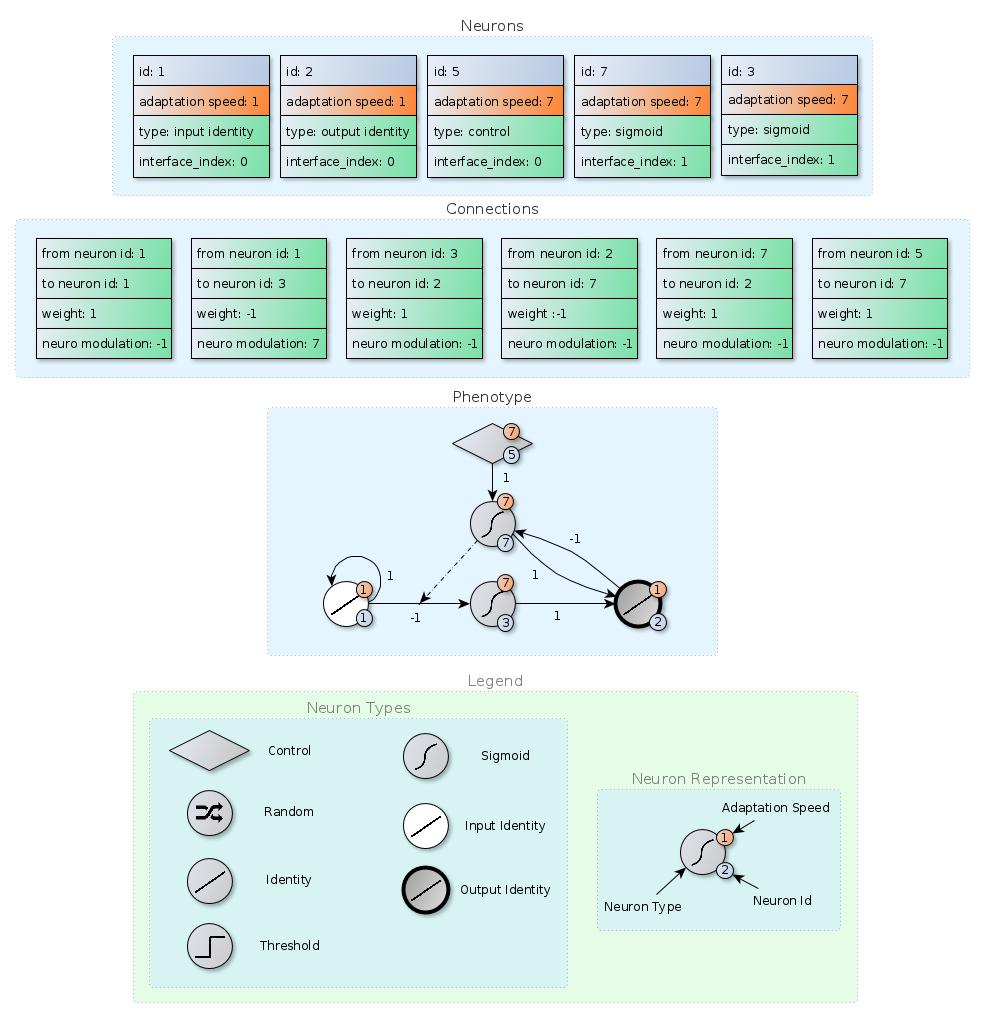
Evolutionary reinforcement learning uses the design flexibility of evolutionary algorithms to tackle the most general paradigm of machine learning, reinforcement learning. SUNA is the first and currently the only algorithm that takes this flexibility to the limit, unifying most of the previous proposed features into one unified neuron model. SUNA is a learning system that evolves its own topology and is able to learn even in non-markov problems.
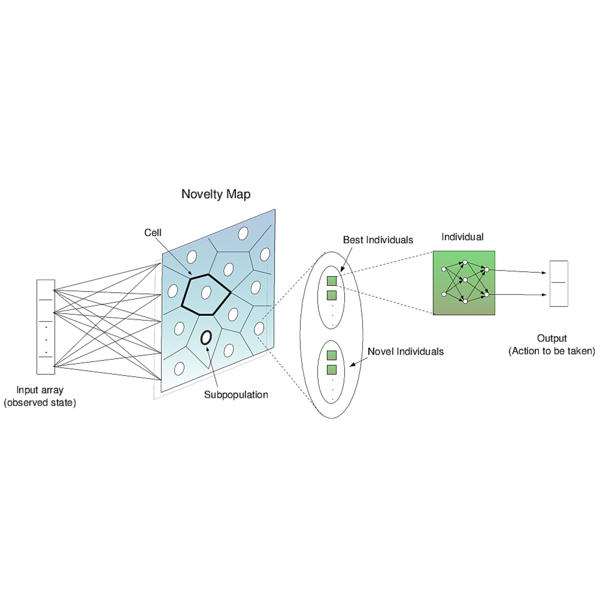
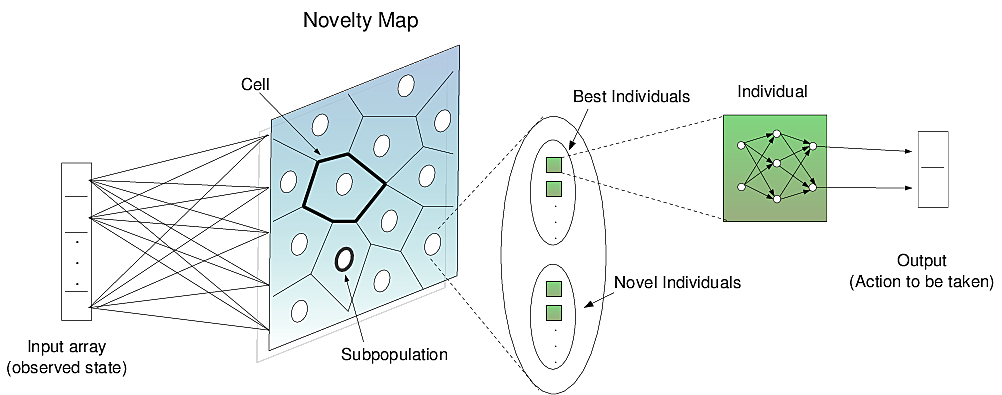
Novelty-Organizing Team of Classifiers is the first method to join both direct policy search and value function approaches into one method.
In fact, it is part of a new class of algorithms called Self-Organization Classifiers which is the first and perhaps the only type of algorithm that can adapt on the fly when a given problem changes (e.g., maze changes in shape). This is possible because states are automatically updated with experience.
Understanding (Attacking) Learning Systems
To further improve current learning systems it is necessary to understand them. Interestingly, attacking learning systems reveal what a learning system understands to be a "horse" or a "ship", helping to understand it. Indeed, in a research that appeared on BBC news, we showed that only one-pixel is necessary to change between classes. In other words, the learned concepts of for example "horse" or "ship" can be changed with only one pixel. This demonstrates that although such neural networks achieve suprahuman recognition in datasets what the neural networks really "understand" to be a "horse" or "ship" is far from intelligent.

Optimization
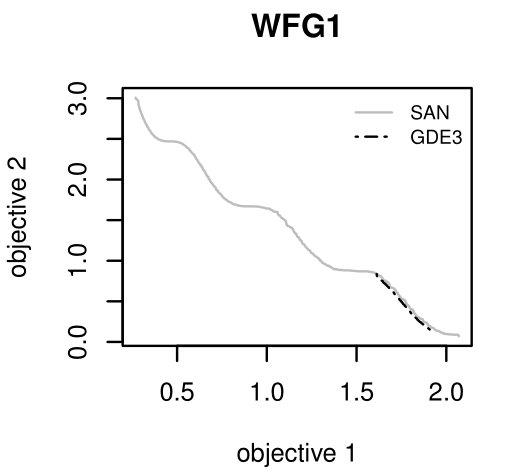
SAN is an extremely simple multi-objective optimization algorithm which outperformed all algorithms in the hardest multi-objective benchmark. When analyzed under Vargas' concept of Optimization Forces it was revealed that the reason for SAN's performance derive from avoiding the conflict inside single population of candidate solutions by using independent subpopulations. Learning algorithms are nothing but optimization algorithms which allow machines to learn and adapt. The next generation of machine learning will certainly have a stronger synergy between them and models to be evolved.

A single bee possesses a vision system that is decades ahead of our algorithms.
Similarly, ants can travel the most complicated fields, create bridges as well as boats while our hexapod robots still have issues with difficult terrains.
Why can't our algorithms behave as well as these relatively simple living beings?
What are we missing?
There is no concluding answer to the above questions but Nature seems to have arrived in such organisms using two important development mechanisms: evolution and learning.
In the same way, my research focus on using evolution and learning to solve a wide range of problems from scheduling to vision and robotics.
The long term objective of my research is to create a general learner: a fully automatic algorithm that is versatile enough to learn and adapt to any circunstance.
Yes, I want to plug it into a robot and see the robot walking better and better.
I want to plug it into an airplane simulation and see it controlling it as well as pilots.
Then I want to plug it into a real airplane and let it adapt to the new system while using the previous knowledge from the simulation.
Last but not least, the general learner would find new ways of doing things when one of its components do not work anymore or when the problem has changed.
In summary, I want to create a new generation of artificial intelligence systems that are as intelligent as a bee.